클라우드 환경 로그수집
📜
온프레미스 환경에서는 로그를 로컬 서버의 log 경로에 파일로 수집하여왔다.
로그 확인이 필요하면 서버에서 해당 날짜의 로그 파일을 열어 보는게 가능했다.
클라우드 서버에서는 서버가 분산처리 되어있다.
개수가 여러개라도 하나씩 들어가서 파일을 찾아 볼 수 있다면 그것은 가능하다.
하지만 Auto-Scaling을 염두해두었다면, 내가 모르는 사이에 서버가 삭제된다.
그렇기 때문에 로그를 따로 수집해야한다.
ELK? EFK?
우선 ELK, EFK 모두 E와 K는 Elasticsearch와 Kibana를 뜻한다.
가운데 L은 Logstash , F는 Fluentd 를 대체한다.
ELK, EFK는 3가지 프로그램을 이용하는 스택을 뜻한다.
Elasticsearch (데이터 색인)
Apache Lucene(아파치 루씬) 기반의 Java 오픈 소스 분산 검색 엔진
성능이 아주 좋은 검색 엔진이기 때문에 대량의 데이터를 저장, 검색, 분석 할 때 사용하기 좋다.
ELK or EFK 에서는 수집(L/F)된 로그에서 데이터를 검색 및 집계하여 필요한 정보를 획득하는데 사용된다.
* 7.10 이전에는 Apache2.0 라이센스였으나, 이후에는 SSPL 라이센스이기 때문에 확인 후 사용이 필요하다.
Kibana (데이터 모니터링)
Elastic Stack 기반으로 구축된 오픈소스 프론트엔드 애플리케이션
Elasticsearch에서 색인된 데이터를 검색하여 분석 및 시각화 하는 플랫폼이다.
Logstatsh (로그 수집기)
Elastic Stack의 일부로 다양한 입력 소스에서 로그를 수집하고, 필터링하고, 변환한 후 다양한 출력으로 보낼 수 있다.
Logstash는 강력한 필터링 및 변환 기능을 제공하며, 다양한 플러그인을 통해 확장 가능
이러한 특징으로 인해 Logstash는 복잡한 로그 처리 및 ETL(Extract, Transform, Load) 작업에 적합한 경우가 많다.
그러나 Logstash는 자바로 작성되어 있어서 메모리 사용량이 많고 상대적으로 무거운 리소스를 요구할 수 있다.
온프레미스 환경, 모놀리식 어플리케이션에서 자주 사용
Fluentd (로그 수집기)
경량 로그 수집기로서, 로그 데이터의 수집, 전송 및 저장에 중점
로그 데이터를 다양한 소스에서 수집하고, 필터링하여 다양한 목적지로 전송할 수 있다.
다양한 플러그인을 통해 확장 가능하며, 여러 프로그래밍 언어로 작성된 플러그인을 지원
간단한 설정 및 배포가 가능하며, 쿠버네티스 클러스터와의 통합이 용이하다는 장점
도커 또는 쿠버네티스 환경, MSA 어플리케이션에서 자주 사용
🎯 결론
모놀리식 어플리케이션에서 사용 목적 : ELK 가 더 많이 사용
MSA 또는 Kubernetes/Docker 에서 사용 목적 : EFK 가 더 많이 사용
EFK 구축하기
ElasticSearch 구축하기
elasticSearch.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
apiVersion: apps/v1
kind: Deployment
metadata:
name: elasticsearch
labels:
app: elasticsearch
spec:
replicas: 1
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: elastic/elasticsearch:7.10.1
env:
- name: discovery.type
value: "single-node"
ports:
- containerPort: 9200
- containerPort: 9300
---
apiVersion: v1
kind: Service
metadata:
labels:
app: elasticsearch
name: elasticsearch-svc
namespace: default
spec:
ports:
- name: elasticsearch-rest
nodePort: 30920
port: 9200
protocol: TCP
targetPort: 9200
- name: elasticsearch-nodecom
nodePort: 30930
port: 9300
protocol: TCP
targetPort: 9300
selector:
app: elasticsearch
type: NodePort
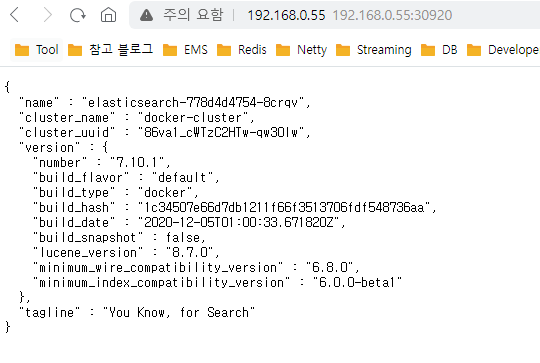
elasticsearch 실행 파일 작성 및 배포
배포 후 접속하면 아래와 같은 상태를 확인 할 수 있다. (9200 포트로 접속)
Kibana 구축하기
kibana.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
labels:
app: kibana
spec:
replicas: 1
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: elastic/kibana:7.10.1
env:
- name: SERVER_NAME
value: "kibana.kubenetes.example.com"
- name: ELASTICSEARCH_HOSTS
value: "http://elasticsearch-svc.default.svc.cluster.local:9200"
ports:
- containerPort: 5601
---
apiVersion: v1
kind: Service
metadata:
labels:
app: kibana
name: kibana-svc
namespace: default
spec:
ports:
- nodePort: 30561
port: 5601
protocol: TCP
targetPort: 5601
selector:
app: kibana
type: NodePort
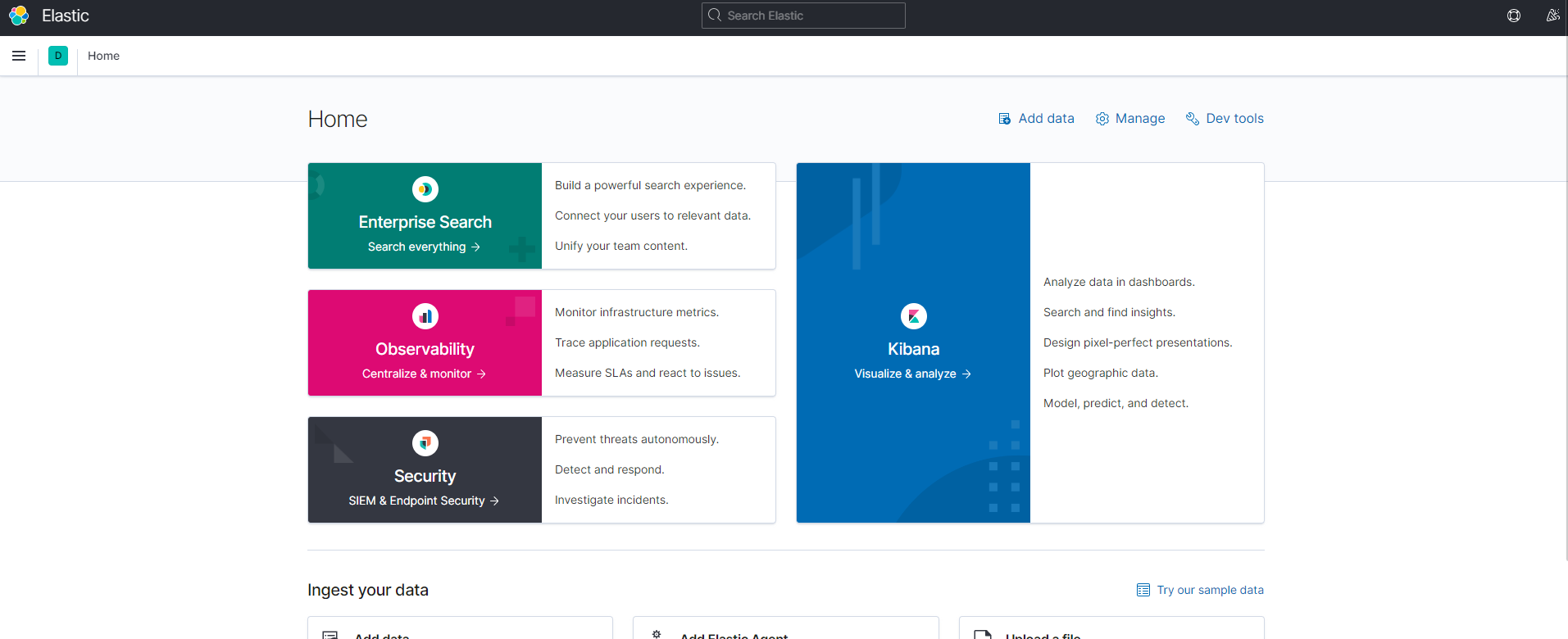
kibana 실행파일 작성 및 배포
배포 후 접속하면 아래와 같은 상태를 확인 할 수 있다.
Fluentd 구축하기
fluentd-configmap.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
namespace: kube-system
labels:
k8s-app: fluentd-logging
version: v1
kubernetes.io/cluster-service: "true"
data:
kubernetes.conf: |
# AUTOMATICALLY GENERATED
# DO NOT EDIT THIS FILE DIRECTLY, USE /templates/conf/kubernetes.conf.erb
<label @FLUENT_LOG>
<match fluent.**>
@type null
@id ignore_fluent_logs
</match>
</label>
<source>
@type tail
@id in_tail_container_logs
path /var/log/containers/*.log
pos_file /var/log/fluentd-containers.log.pos
tag "#{ENV['FLUENT_CONTAINER_TAIL_TAG'] || 'kubernetes.*'}"
format /^(?<time>.+) (?<stream>stdout|stderr)( (?<logtag>.))? (?<log>.*)$/
</source>
<source>
@type tail
@id in_tail_minion
path /var/log/salt/minion
pos_file /var/log/fluentd-salt.pos
tag salt
<parse>
@type regexp
expression /^(?<time>[^ ]* [^ ,]*)[^\[]*\[[^\]]*\]\[(?<severity>[^ \]]*) *\] (?<message>.*)$/
time_format %Y-%m-%d %H:%M:%S
</parse>
</source>
<source>
@type tail
@id in_tail_startupscript
path /var/log/startupscript.log
pos_file /var/log/fluentd-startupscript.log.pos
tag startupscript
<parse>
@type syslog
</parse>
</source>
<source>
@type tail
@id in_tail_docker
path /var/log/docker.log
pos_file /var/log/fluentd-docker.log.pos
tag docker
<parse>
@type regexp
expression /^time="(?<time>[^)]*)" level=(?<severity>[^ ]*) msg="(?<message>[^"]*)"( err="(?<error>[^"]*)")?( statusCode=($<status_code>\d+))?/
</parse>
</source>
<source>
@type tail
@id in_tail_etcd
path /var/log/etcd.log
pos_file /var/log/fluentd-etcd.log.pos
tag etcd
<parse>
@type none
</parse>
</source>
<source>
@type tail
@id in_tail_kubelet
multiline_flush_interval 5s
path /var/log/kubelet.log
pos_file /var/log/fluentd-kubelet.log.pos
tag kubelet
<parse>
@type kubernetes
</parse>
</source>
<source>
@type tail
@id in_tail_kube_proxy
multiline_flush_interval 5s
path /var/log/kube-proxy.log
pos_file /var/log/fluentd-kube-proxy.log.pos
tag kube-proxy
<parse>
@type kubernetes
</parse>
</source>
<source>
@type tail
@id in_tail_kube_apiserver
multiline_flush_interval 5s
path /var/log/kube-apiserver.log
pos_file /var/log/fluentd-kube-apiserver.log.pos
tag kube-apiserver
<parse>
@type kubernetes
</parse>
</source>
<source>
@type tail
@id in_tail_kube_controller_manager
multiline_flush_interval 5s
path /var/log/kube-controller-manager.log
pos_file /var/log/fluentd-kube-controller-manager.log.pos
tag kube-controller-manager
<parse>
@type kubernetes
</parse>
</source>
<source>
@type tail
@id in_tail_kube_scheduler
multiline_flush_interval 5s
path /var/log/kube-scheduler.log
pos_file /var/log/fluentd-kube-scheduler.log.pos
tag kube-scheduler
<parse>
@type kubernetes
</parse>
</source>
<source>
@type tail
@id in_tail_rescheduler
multiline_flush_interval 5s
path /var/log/rescheduler.log
pos_file /var/log/fluentd-rescheduler.log.pos
tag rescheduler
<parse>
@type kubernetes
</parse>
</source>
<source>
@type tail
@id in_tail_glbc
multiline_flush_interval 5s
path /var/log/glbc.log
pos_file /var/log/fluentd-glbc.log.pos
tag glbc
<parse>
@type kubernetes
</parse>
</source>
<source>
@type tail
@id in_tail_cluster_autoscaler
multiline_flush_interval 5s
path /var/log/cluster-autoscaler.log
pos_file /var/log/fluentd-cluster-autoscaler.log.pos
tag cluster-autoscaler
<parse>
@type kubernetes
</parse>
</source>
# Example:
# 2017-02-09T00:15:57.992775796Z AUDIT: id="90c73c7c-97d6-4b65-9461-f94606ff825f" ip="104.132.1.72" method="GET" user="kubecfg" as="<self>" asgroups="<lookup>" namespace="default" uri="/api/v1/namespaces/default/pods"
# 2017-02-09T00:15:57.993528822Z AUDIT: id="90c73c7c-97d6-4b65-9461-f94606ff825f" response="200"
<source>
@type tail
@id in_tail_kube_apiserver_audit
multiline_flush_interval 5s
path /var/log/kubernetes/kube-apiserver-audit.log
pos_file /var/log/kube-apiserver-audit.log.pos
tag kube-apiserver-audit
<parse>
@type multiline
format_firstline /^\S+\s+AUDIT:/
# Fields must be explicitly captured by name to be parsed into the record.
# Fields may not always be present, and order may change, so this just looks
# for a list of key="\"quoted\" value" pairs separated by spaces.
# Unknown fields are ignored.
# Note: We can't separate query/response lines as format1/format2 because
# they don't always come one after the other for a given query.
format1 /^(?<time>\S+) AUDIT:(?: (?:id="(?<id>(?:[^"\\]|\\.)*)"|ip="(?<ip>(?:[^"\\]|\\.)*)"|method="(?<method>(?:[^"\\]|\\.)*)"|user="(?<user>(?:[^"\\]|\\.)*)"|groups="(?<groups>(?:[^"\\]|\\.)*)"|as="(?<as>(?:[^"\\]|\\.)*)"|asgroups="(?<asgroups>(?:[^"\\]|\\.)*)"|namespace="(?<namespace>(?:[^"\\]|\\.)*)"|uri="(?<uri>(?:[^"\\]|\\.)*)"|response="(?<response>(?:[^"\\]|\\.)*)"|\w+="(?:[^"\\]|\\.)*"))*/
time_format %Y-%m-%dT%T.%L%Z
</parse>
</source>
<filter kubernetes.**>
@type kubernetes_metadata
@id filter_kube_metadata
kubernetes_url "#{ENV['FLUENT_FILTER_KUBERNETES_URL'] || 'https://' + ENV.fetch('KUBERNETES_SERVICE_HOST') + ':' + ENV.fetch('KUBERNETES_SERVICE_PORT') + '/api'}"
verify_ssl "#{ENV['KUBERNETES_VERIFY_SSL'] || true}"
ca_file "#{ENV['KUBERNETES_CA_FILE']}"
skip_labels "#{ENV['FLUENT_KUBERNETES_METADATA_SKIP_LABELS'] || 'false'}"
skip_container_metadata "#{ENV['FLUENT_KUBERNETES_METADATA_SKIP_CONTAINER_METADATA'] || 'false'}"
skip_master_url "#{ENV['FLUENT_KUBERNETES_METADATA_SKIP_MASTER_URL'] || 'false'}"
skip_namespace_metadata "#{ENV['FLUENT_KUBERNETES_METADATA_SKIP_NAMESPACE_METADATA'] || 'false'}"
watch "#{ENV['FLUENT_KUBERNETES_WATCH'] || 'true'}"
</filter>
fluent.conf: |
# AUTOMATICALLY GENERATED
# DO NOT EDIT THIS FILE DIRECTLY, USE /templates/conf/fluent.conf.erb
@include "#{ENV['FLUENTD_SYSTEMD_CONF'] || 'systemd'}.conf"
@include "#{ENV['FLUENTD_PROMETHEUS_CONF'] || 'prometheus'}.conf"
@include kubernetes.conf
@include conf.d/*.conf
<match **>
@type elasticsearch
@id out_es
@log_level info
include_tag_key true
host "#{ENV['FLUENT_ELASTICSEARCH_HOST']}"
port "#{ENV['FLUENT_ELASTICSEARCH_PORT']}"
path "#{ENV['FLUENT_ELASTICSEARCH_PATH']}"
scheme "#{ENV['FLUENT_ELASTICSEARCH_SCHEME'] || 'http'}"
ssl_verify "#{ENV['FLUENT_ELASTICSEARCH_SSL_VERIFY'] || 'true'}"
ssl_version "#{ENV['FLUENT_ELASTICSEARCH_SSL_VERSION'] || 'TLSv1_2'}"
user "#{ENV['FLUENT_ELASTICSEARCH_USER'] || use_default}"
password "#{ENV['FLUENT_ELASTICSEARCH_PASSWORD'] || use_default}"
reload_connections "#{ENV['FLUENT_ELASTICSEARCH_RELOAD_CONNECTIONS'] || 'false'}"
reconnect_on_error "#{ENV['FLUENT_ELASTICSEARCH_RECONNECT_ON_ERROR'] || 'true'}"
reload_on_failure "#{ENV['FLUENT_ELASTICSEARCH_RELOAD_ON_FAILURE'] || 'true'}"
log_es_400_reason "#{ENV['FLUENT_ELASTICSEARCH_LOG_ES_400_REASON'] || 'false'}"
logstash_prefix "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_PREFIX'] || 'logstash'}"
logstash_dateformat "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_DATEFORMAT'] || '%Y.%m.%d'}"
logstash_format "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_FORMAT'] || 'true'}"
index_name "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_INDEX_NAME'] || 'logstash'}"
target_index_key "#{ENV['FLUENT_ELASTICSEARCH_TARGET_INDEX_KEY'] || use_nil}"
type_name "#{ENV['FLUENT_ELASTICSEARCH_LOGSTASH_TYPE_NAME'] || 'fluentd'}"
include_timestamp "#{ENV['FLUENT_ELASTICSEARCH_INCLUDE_TIMESTAMP'] || 'false'}"
template_name "#{ENV['FLUENT_ELASTICSEARCH_TEMPLATE_NAME'] || use_nil}"
template_file "#{ENV['FLUENT_ELASTICSEARCH_TEMPLATE_FILE'] || use_nil}"
template_overwrite "#{ENV['FLUENT_ELASTICSEARCH_TEMPLATE_OVERWRITE'] || use_default}"
sniffer_class_name "#{ENV['FLUENT_SNIFFER_CLASS_NAME'] || 'Fluent::Plugin::ElasticsearchSimpleSniffer'}"
request_timeout "#{ENV['FLUENT_ELASTICSEARCH_REQUEST_TIMEOUT'] || '5s'}"
suppress_type_name "#{ENV['FLUENT_ELASTICSEARCH_SUPPRESS_TYPE_NAME'] || 'true'}"
enable_ilm "#{ENV['FLUENT_ELASTICSEARCH_ENABLE_ILM'] || 'false'}"
ilm_policy_id "#{ENV['FLUENT_ELASTICSEARCH_ILM_POLICY_ID'] || use_default}"
ilm_policy "#{ENV['FLUENT_ELASTICSEARCH_ILM_POLICY'] || use_default}"
ilm_policy_overwrite "#{ENV['FLUENT_ELASTICSEARCH_ILM_POLICY_OVERWRITE'] || 'false'}"
<buffer>
flush_thread_count "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_FLUSH_THREAD_COUNT'] || '8'}"
flush_interval "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_FLUSH_INTERVAL'] || '5s'}"
chunk_limit_size "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_CHUNK_LIMIT_SIZE'] || '2M'}"
queue_limit_length "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_QUEUE_LIMIT_LENGTH'] || '32'}"
retry_max_interval "#{ENV['FLUENT_ELASTICSEARCH_BUFFER_RETRY_MAX_INTERVAL'] || '30'}"
retry_forever true
</buffer>
</match>
( fluentd logformat 오류로 인해 부득이하게 fluent.conf 와 kubernetes.conf 파일을 전부 가져왔다. 28Line format 설정)
fluentd의 logformat 검증은 https://fluentular.herokuapp.com/ 에서 가능
fluentd.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: fluentd
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: fluentd
namespace: kube-system
rules:
- apiGroups:
- ""
resources:
- pods
- namespaces
verbs:
- get
- list
- watch
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: fluentd
roleRef:
kind: ClusterRole
name: fluentd
apiGroup: rbac.authorization.k8s.io
subjects:
- kind: ServiceAccount
name: fluentd
namespace: kube-system
---
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-system
labels:
k8s-app: fluentd-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
selector:
matchLabels:
k8s-app: fluentd-logging
version: v1
template:
metadata:
labels:
k8s-app: fluentd-logging
version: v1
kubernetes.io/cluster-service: "true"
spec:
serviceAccount: fluentd
serviceAccountName: fluentd
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd
image: fluent/fluentd-kubernetes-daemonset:v1.11.5-debian-elasticsearch7-1.1
env:
- name: FLUENT_ELASTICSEARCH_HOST
value: "elasticsearch-svc.default.svc.cluster.local"
- name: FLUENT_ELASTICSEARCH_PORT
value: "9200"
- name: FLUENT_ELASTICSEARCH_SCHEME
value: "http"
- name: FLUENTD_SYSTEMD_CONF
value: disable
- name: FLUENT_UID
value: "0"
- name: FLUENT_CONTAINER_TAIL_EXCLUDE_PATH
value: /var/log/containers/fluent*
- name: FLUENT_CONTAINER_TAIL_PARSER_TYPE
value: /^(?<time>.+) (?<stream>stdout|stderr)( (?<logtag>.))? (?<log>.*)$/
resources:
limits:
memory: 1024Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
- name: config-source
mountPath: /fluentd/etc
terminationGracePeriodSeconds: 30
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: config-source
configMap:
name: fluentd-config
fluentd 실행 파일 작성 및 배포
host 서버에서 102Line의 경로에 실제 컨테이너별 log 파일을 확인 할 수 있다.
이렇게 각 노드당 host 서버의 log 파일을 수집한다.
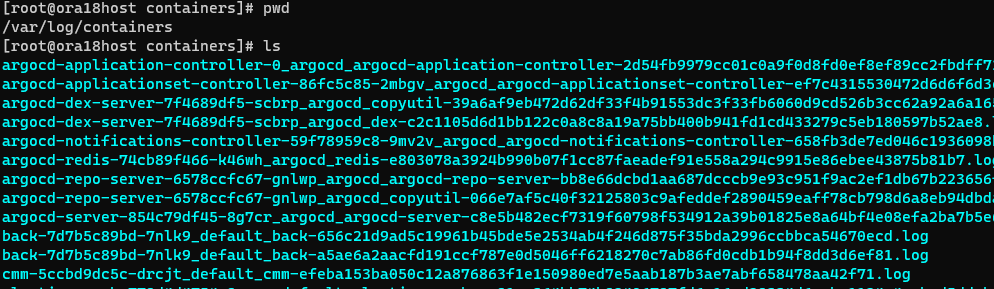
/var/log/containers 아래에 cmm-{containreId} 로 생긴 log 파일을 확인 할 수 있다.
⚠️ Fluentd는 로그 수집기의 역할로 클러스터 내 각 노드마다 1개씩 배포되어있어야 모든 노드의 로그를 수집할 수 있기 때문에 Daemonset으로 배포되어야한다.
배포 후 아래와 같이 kube-system 네임스페이스에서 daemonset을 조회할 수 있다.

로그 시각화
인덱스 패턴 생성
kibana UI에 접속, Management > Stack Management > Kibana > Index Patterns
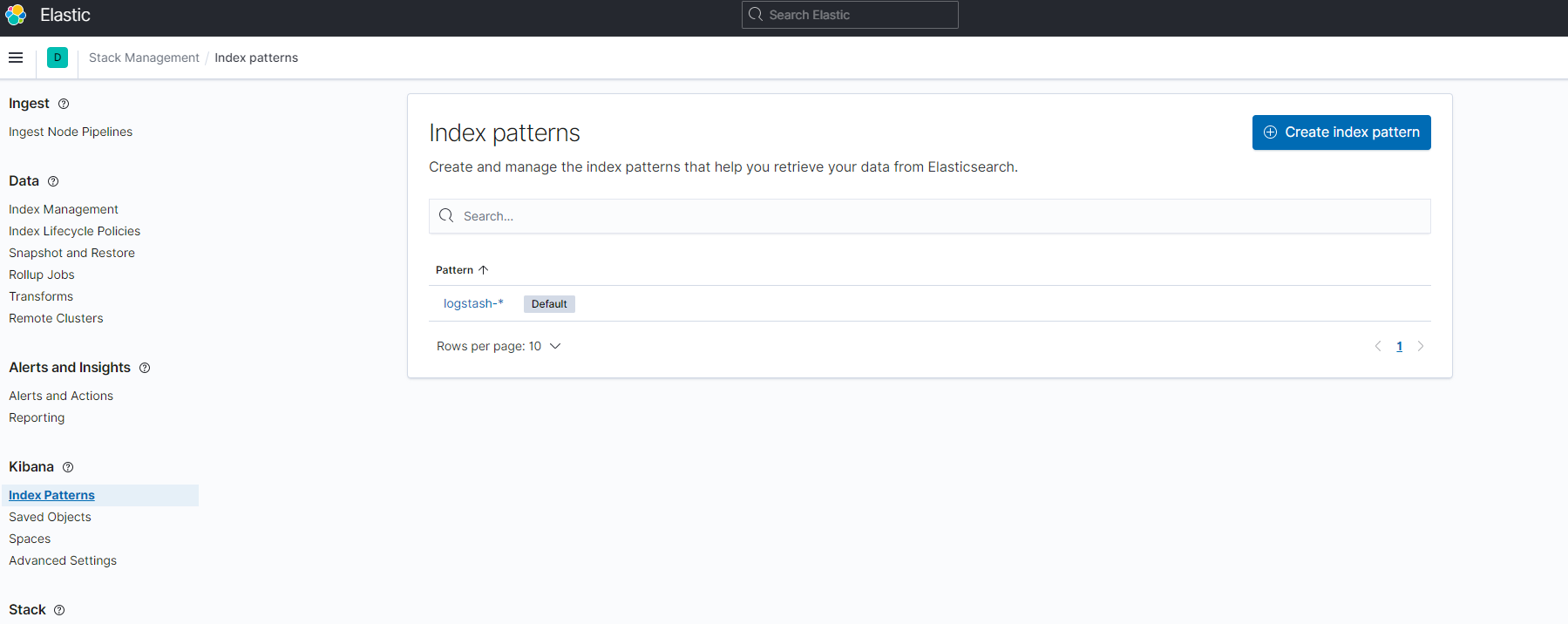
+ Create index pattern 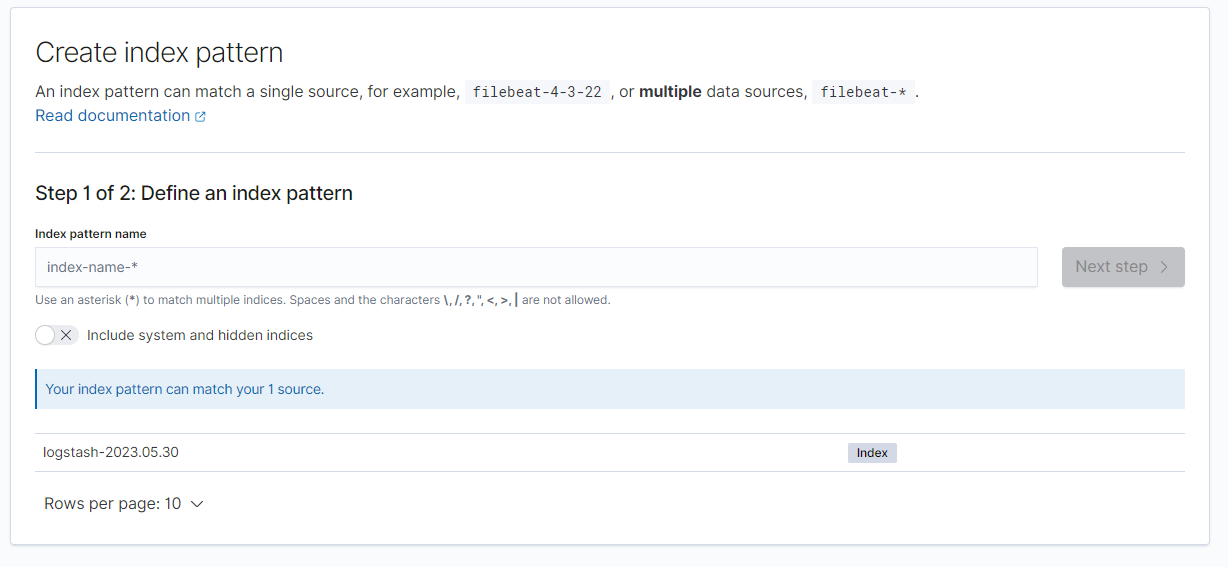
아래 Your index pattern can match your 1 source. 라며 등록 가능한 index pattern을 보여준다.
index pattern name에 logstash-* 로 등록 후 Next step으로 넘어간다.
Configure settings 에서는 Time fileld를 @timestamp 로 선택하여 index pattern 생성을 완료한다.
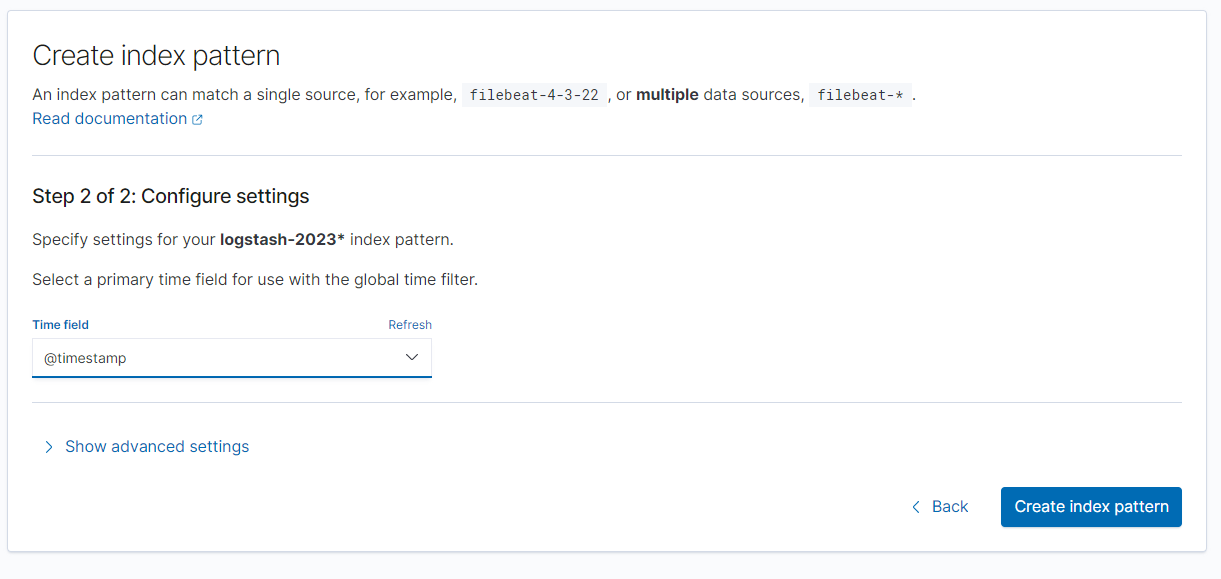
로그 시각화
Kibana > Discover 에서 아래와 같이 원하는 조건, 시간으로 수집된 로그를 UI로 확인 할 수 있다.
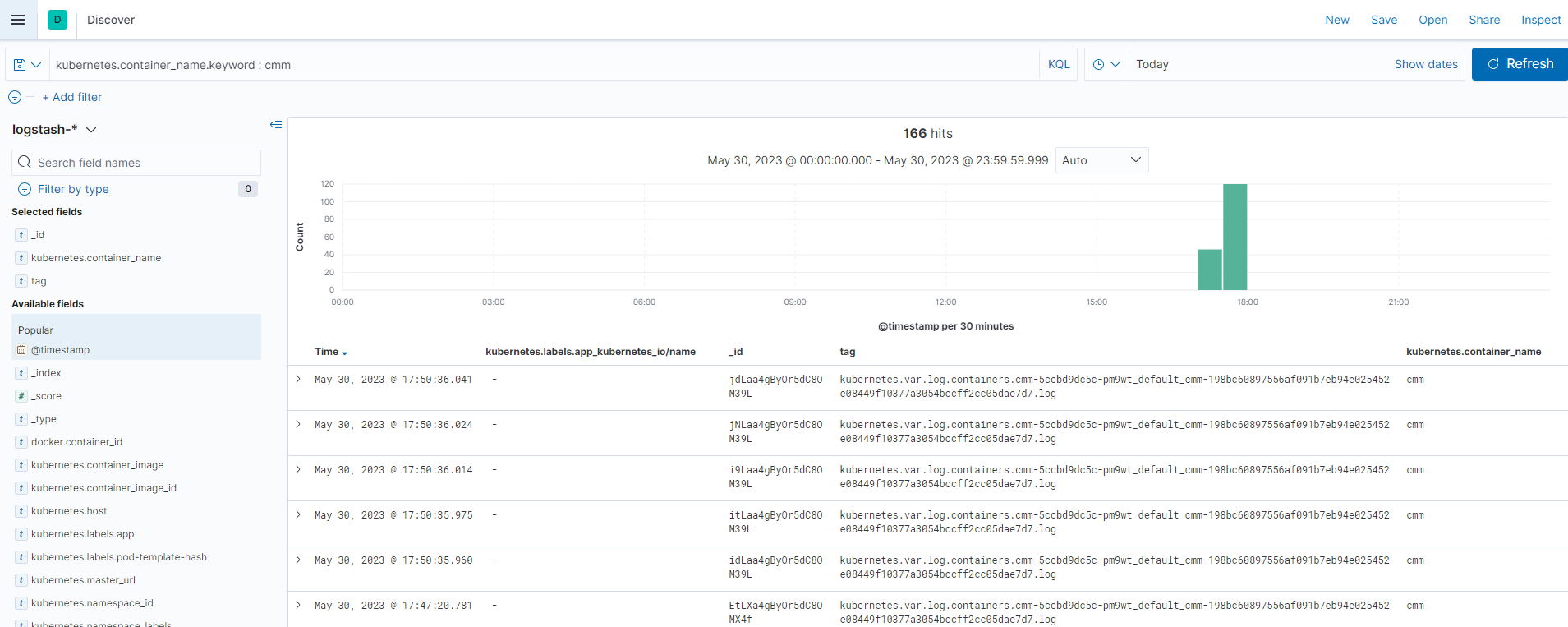
아래 로그 목록을 선택하면 상세 내용을 확인 할 수 있다.
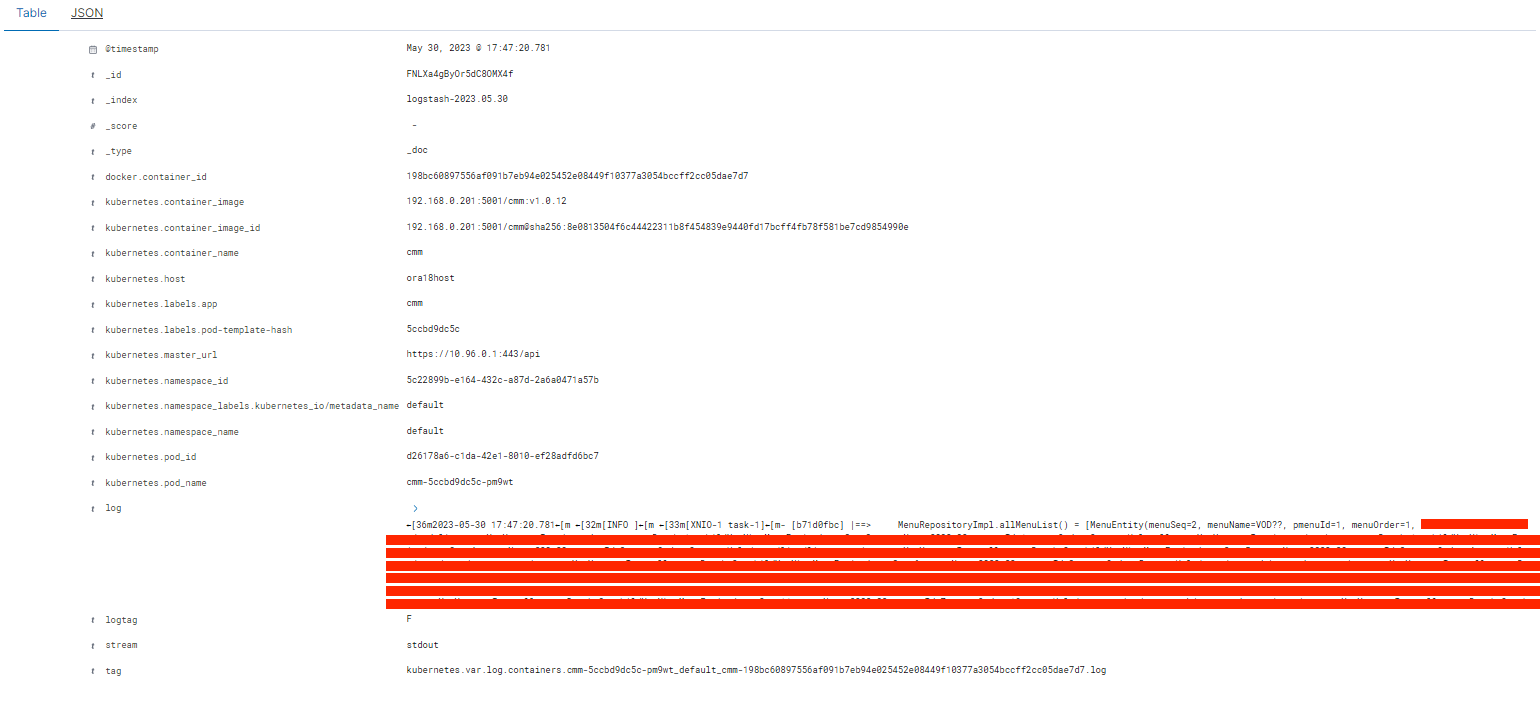
한글 깨짐은 서버 인코딩 설정 확인 필요